Enabling Systematic Evaluation of Agentic AI in Real Web Environments
40,000+ human preference evaluations delivered to benchmark agentic AI across multi-turn reasoning, web grounding, and real-world browsing tasks.
.webp)
40,000+
9 dimension
45-90 mins
Deccan delivered a training-grade human evaluation dataset to support development of agentic, multimodal AI systems operating over real web environments. The work focused on producing structured preference signals that expose grounding, reasoning, and execution failures across multi-turn tasks, with evaluation aligned to training relevance rather than surface response quality.
The Problem
Evaluating agentic, multimodal AI systems differs from evaluating single-turn or text-only models. Each evaluation must account for how an agent interacts with real websites, interprets page-level visual and textual content, and maintains intent across multi-turn trajectories.
Fluent final responses often mask failures in grounding, source usage, or multi-step reasoning. From outputs alone, it is difficult to determine whether an agent accessed the correct webpages or relied on visible content. This limits the usefulness of traditional evaluation for model iteration.
Evaluation complexity increases further when tasks span multiple webpages, screenshots, and extended interaction history, requiring sustained human judgment rather than checklist-based annotation.
Deccan’s Approach
Deccan combined preference-based evaluation with a structured behavioral rubric and a severity-based taxonomy, supported by an execution model designed for high-complexity work.
Each task was evaluated through pairwise human comparison using full conversational context and webpage state. Evaluators produced a preference ranking and a short justification tied to explicit behavioral criteria, preserving both directionality and cause.
Behavioral Rubric and Signal Structure
Agent behavior was evaluated across nine dimensions, selected to reflect how web-grounded, multi-turn agents succeed or fail in practice:
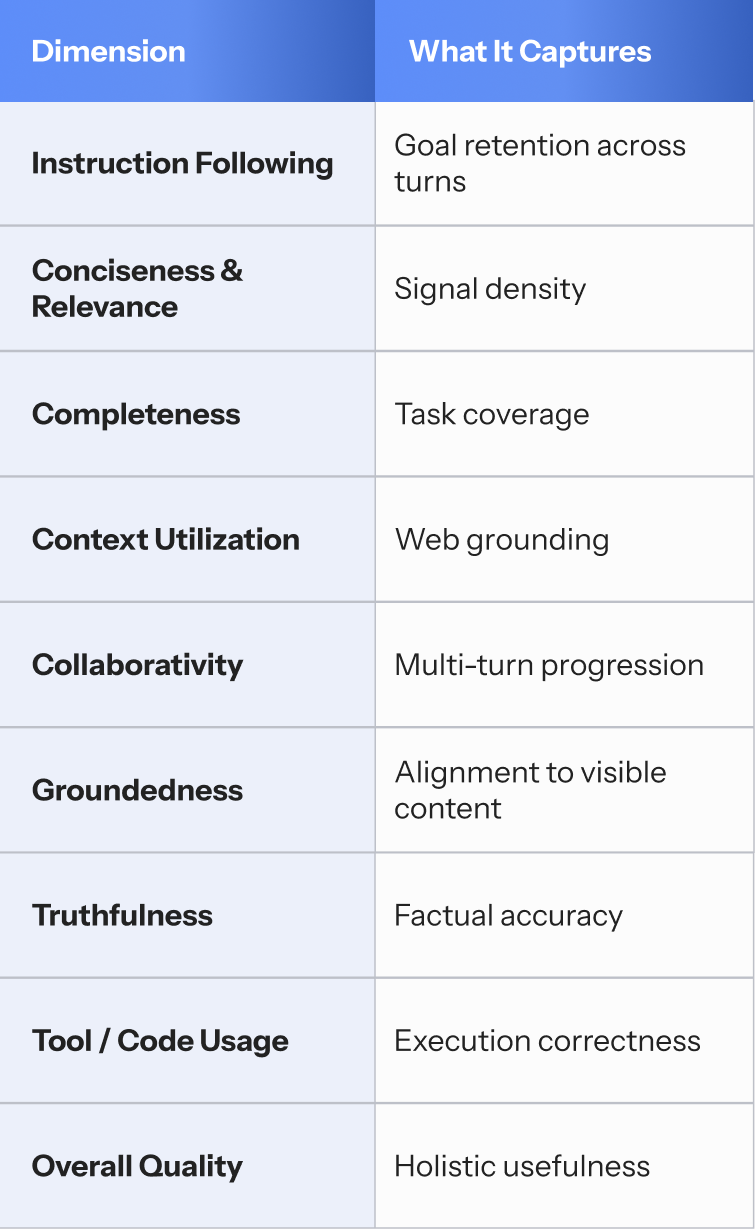
Each dimension was tagged using severity labels (no / minor / major issues), enabling aggregation by failure type without false numerical precision.
Execution and Evaluation
Tasks frequently involved multiple webpages, screenshots, and extended interaction histories. Deccan trained evaluators specifically on web-dependent agent behavior, including access verification, visual interpretation, and trajectory-level failure identification.
Quality control focused on judgment calibration, with evaluator decisions reviewed against rubric definitions and severity criteria. This allowed continuous delivery of preference data without degradation in signal quality.
Key Takeaways
- Agentic AI evaluation requires structured, training-aligned preference signals
- Behavioral decomposition enables localization of failure modes
- High-complexity evaluation depends on calibrated human judgment
- Preference data supports incremental model iteration
Conclusion
This engagement demonstrates that training-grade evaluation for agentic, multimodal AI systems can be delivered at scale when grounded in explicit behavioral rubrics, preference-based judgment, and disciplined execution. Deccan produced a consistent evaluation dataset suitable for frontier model development without relaxing standards as volume increased.
