.png)
We introduce a new framework for end-to-end evaluation of next-gen image generation models
Overview
In the domain of image and design, LLM capabilities have progressed rapidly that underscores the need for robust evaluation frameworks. While foundational benchmarks (T2I-CompBench, T2I-CompBench++, HEIM, Pick-aPic) reveal gaps in composition fidelity and quality, they fail to assess visual aesthetics and systematic instruction-following capabilities, therefore falling short for trust and deployment reliability.
In response, we introduce a taxonomy-driven benchmark for text-to-image generation models with rubrics assessing adherence, attribute accuracy, spatial reasoning, and realism-aesthetic balance.
Our initial private validation study consists of 40 novel tasks designed and evaluated by professional photographers and digital imaging experts using multi-annotator QC.
Data samples associated with this study can be accessed here: Link
Methodology
{{method}}
Key Findings
Our evaluation, structured across comprehensive rubrics, reveals a closely contested field.
Nano Banana Pro shows a slight edge in overall consistency with 87.92% score among 5 leading models, followed by GPT Image 1 (86%), Seedream 4.0 (77.76%), Flux.1 Context (77.76%) and Higgsfield Soul (75.01%).
Strategic Model Selection Guide
To help you choose the best tool for your next project, here is a breakdown of what each model is best suited for:
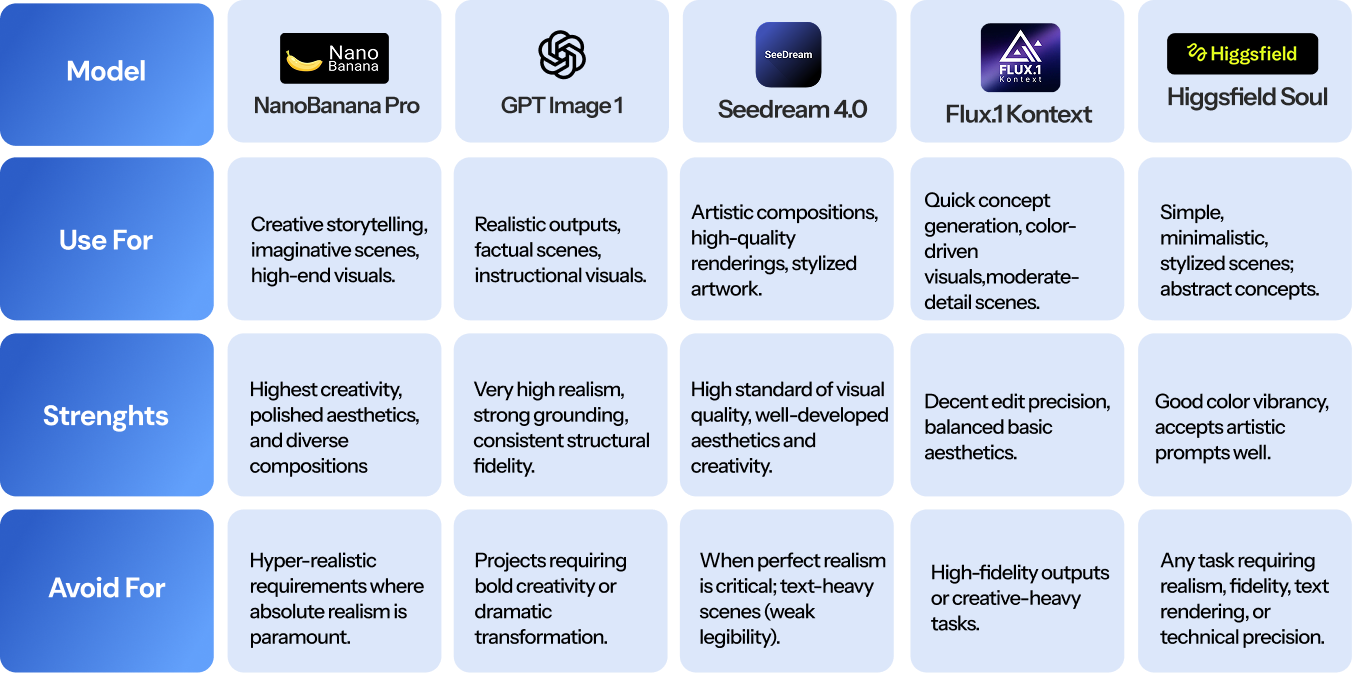
Key Findings by Rubric
The study was structured around four core evaluation rubrics: Visual Aesthetics, Quality Adherence, Creativity & Novelty, and Realism (Fairness & Representation).
.png)
What the rubrics reveal:
- Visual Aesthetics: Nano Banana Pro scored highest (90.12%); Higgsfield Soul's craftsmanship inconsistency limits professional use
- Quality Adherence: GPT Image 1 scored highest (85.97%); text legibility is the industry-wide weak point (64.60% average)
- Creativity: Nano Banana Pro and Seedream 4.0 scored strongest; Higgsfield Soul and Flux.1 Kontext favored safe interpretations
- Realism: GPT Image 1 achieved highest scores with superior lighting and proportions
Key Findings by Task Type
When breaking down performance by task type, the competitive landscape shifts, indicating that model selection should be task-specific:
.png)
Detailed Observations by Category

.png)
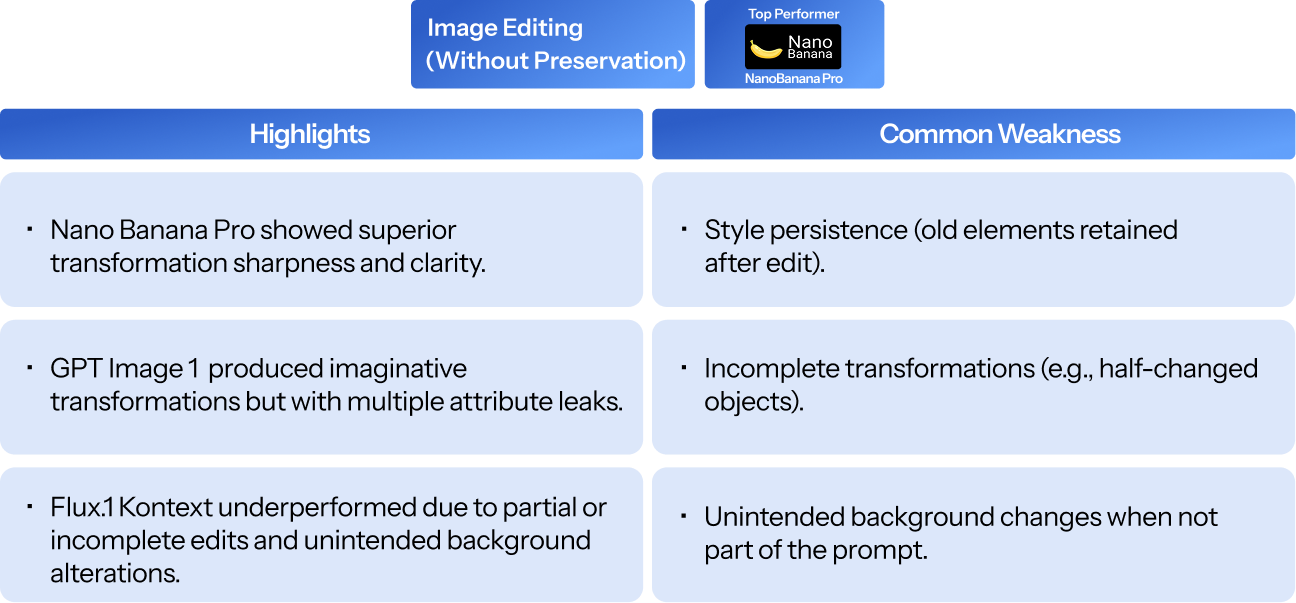
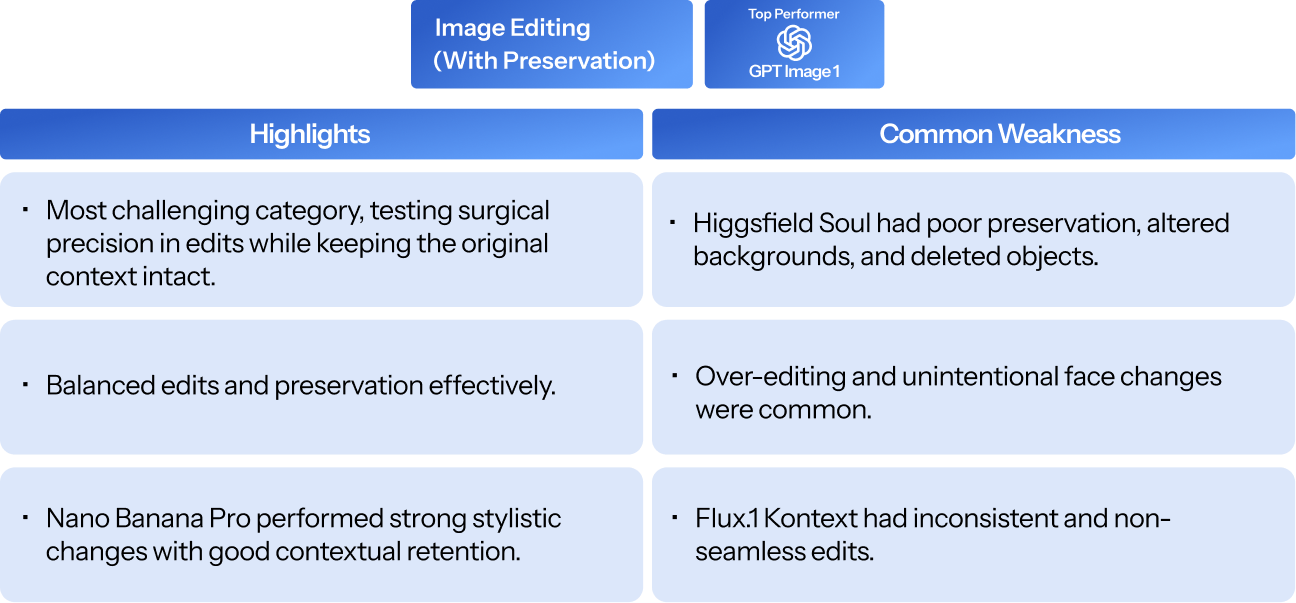
Interpretations
- A clear two-tier structure exists: Nano Banana Pro and GPT Image 1 form the top tier; Seedream 4.0 sits slightly below; Higgsfield Soul and Flux.1 Kontext trail on most dimensions.
- No single model dominates every dimension. GPT Image 1 leads realism/fairness by a wide margin; Nano Banana Pro leads aesthetics, adherence, and creativity. Seedream 4.0 is the strongest in simplicity and artistic style.
- Text legibility (65.51% industry average) and editing-with-preservation are unsolved problems across the board.
- Attribute leak, Misspelling in generated text, and Compositional errors emerged as recurring failure modes across all model families, indicating a consistent behaviour trait.
{{notes}}
Best-fit use cases
- Use this benchmark when: selecting an image generation model for a production pipeline, comparing model capabilities for a specific workflow (e.g., editing vs. generation), or identifying which quality dimensions matter most for your use case.
- Use this benchmark to: demonstrate structured, human-evaluated model comparison methodology to clients or internal stakeholders; surface specific failure modes to guide prompt engineering or model selection.
- Use this benchmark as: a template for custom evaluations — the taxonomy and rubric framework are reusable for new models, new prompts, or domain-specific extensions.
Appendix
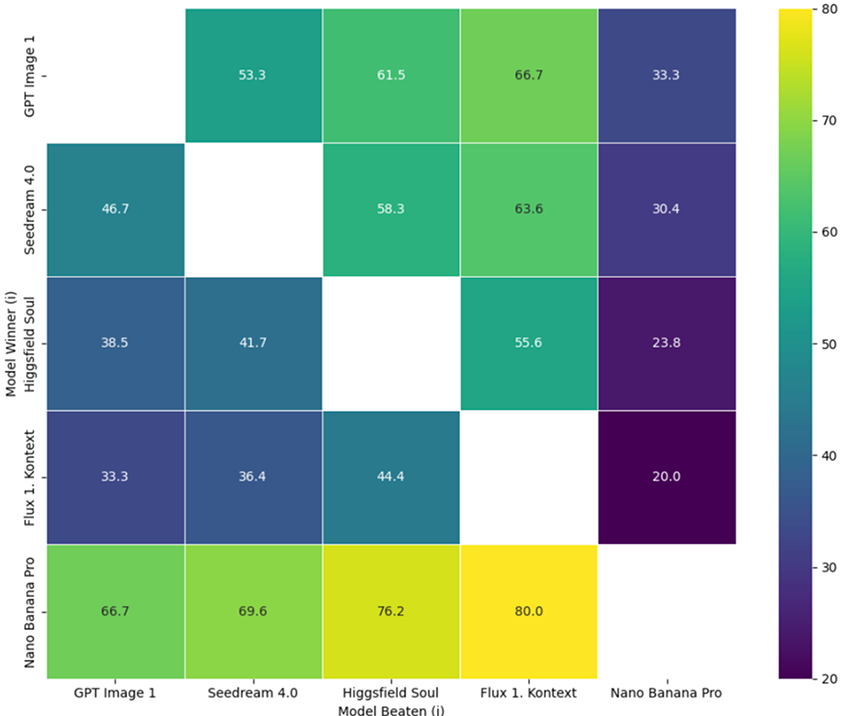
Cell (i, j) = % of wins by model i against model j over the same N prompts. N=40

%20(1).png)
.png)