Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur.
Building Training-Grade Video SFT Dataset at Scale
Delivery Highlights
Overview
Deccan created a training-grade Video SFT dataset to support fine-tuning of prompt-driven video editing models. The work focused on producing source–target video pairs conditioned on text instructions, where each target video applied a specific edit while preserving temporal structure across the full sequence. The dataset was designed to support model learning for controlled video manipulation, stylization, and complex edits, with evaluation and acceptance aligned to training correctness rather than surface quality.
Client
Fortune 500 creative software company
Dataset Type
Supervised Fine - Tuning (SFT)
Domain
Multimodal
Dataset Scale
50,000+ video pairs
Capability
Video SFT
Delivery Highlights
50,000+
training-grade video pairs delivered
100%
adherence to defined acceptance criteria
5 mins
AHT per sample
The Problem
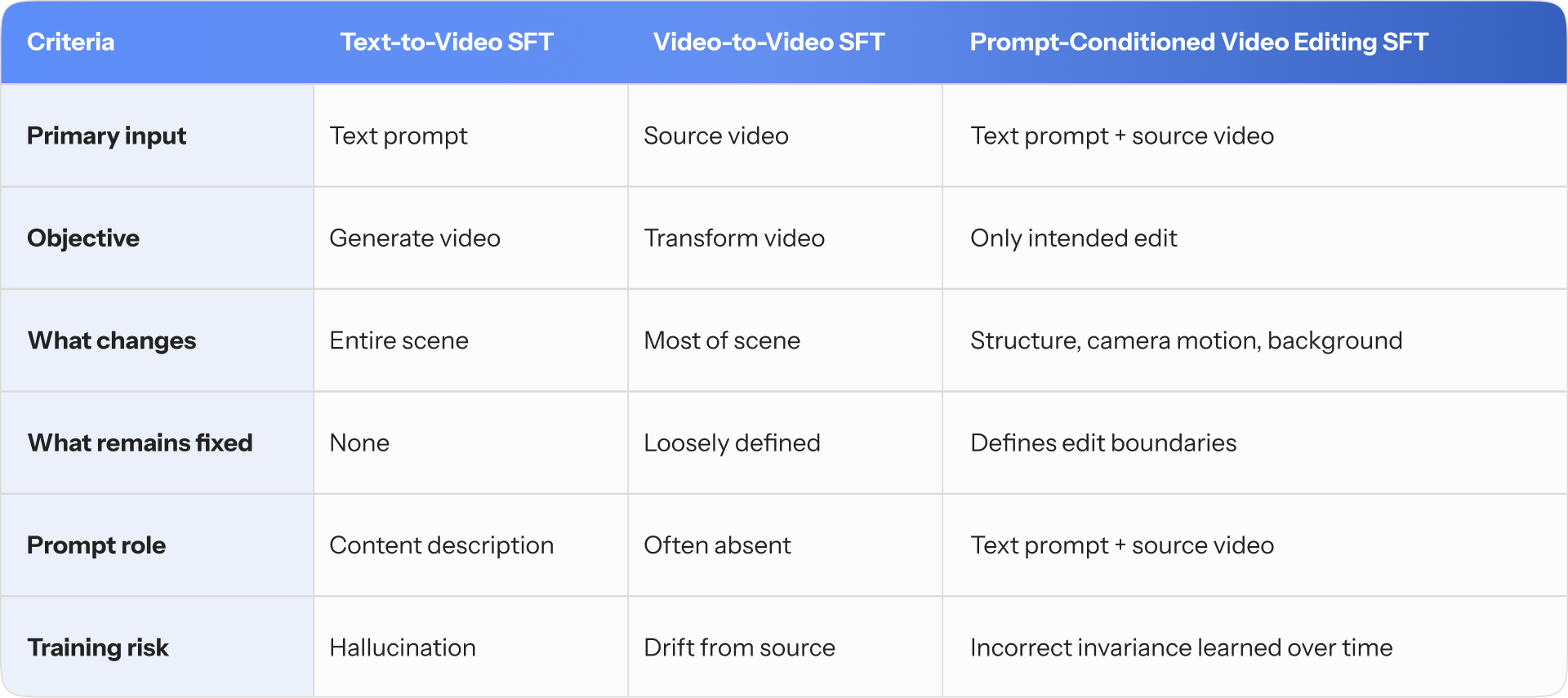
Training video editing models using SFT differs from both text-to-video and video-to-video tasks. Each training example must align three inputs simultaneously: a text instruction, a source video, and a target video.
The challenge lies in enforcing controlled change. The model must apply the edit specified by the prompt while preserving temporal structure across the entire sequence. Errors are often subtle, accumulate over time, and can introduce incorrect training signals even when individual frames appear acceptable.
Current video models struggle to reliably perform this type of constrained transformation at scale. As a result, high-quality, training-grade SFT data becomes critical. Deccan leveraged its in-house video SFT capabilities to design and produce a dataset specifically structured to help models learn precise, prompt-aligned edits without violating structural consistency.
Comparison of Training Paradigms
Deccan’s Approach
Deccan combined a clear taxonomy of video edit types with a structured delivery process designed to enforce training correctness at scale.
Edit Taxonomy & Constraints
Manipulation (localized object addition or removal)
Stylization (appearance changes applied consistently over time)
Complex / VFX-style edits (motion- or interaction-heavy changes)
Each category imposed different constraints on what could change and what had to remain invariant. These constraints informed prompt design, evaluation criteria, and acceptance standards.
Prompt-Conditioned Generation
Each sample paired a source video with a highly constrained text prompt specifying the edit. Prompts were written in natural language to reflect how end users describe video edits in real environments, ensuring that the resulting SFT dataset trains models to respond to real-world instructions rather than synthetic command formats. Prompt structure varied by edit category and was designed to explicitly bound the transformation.
Generated outputs were treated as candidates, not final artifacts, and entered a delivery pipeline built to enforce these constraints.
Multi-Stage Evaluation and Regeneration
Every generated video passed through multiple evaluation stages aligned to training correctness:
Early rejection of structurally unsafe outputs
Structured evaluation based on objective rubrics defined in accordance with client requirements, assessing temporal consistency, structural preservation, and prompt adherence
Independent quality checks as a second layer of human evaluation to maintain consistent acceptance standards
This two-layer human review process ensured that only samples meeting defined criteria progressed into the final SFT dataset.
Key Takeaways
Training-grade Video SFT requires explicit control over what must remain unchanged
Video editing SFT benefits from separating tasks into clear edit categories
Prompt design directly shapes training outcomes
Evaluation must account for temporal behavior across full videos
With the right structure, Video SFT can scale without eroding quality
Conclusion
This engagement demonstrates that prompt-conditioned Video SFT can be delivered at scale when grounded in clear edit definitions, constrained prompt design, and evaluation aligned to how video models learn over time. By combining taxonomy-driven task decomposition with disciplined execution, Deccan produced a large, consistent dataset suitable for training video editing models without relaxing standards as volume increased.