.png)
This study evaluates instruction-following reliability in frontier models under controlled, multi-constraint conditions.
Overview
We evaluated instruction-following on GPT 5.2 High and Gemini 3.0 Pro using 278 expertcrafted prompts, scored by three independent human annotators per response. GPT scored ~11 points higher overall, but had higher format violation rates than Gemini across every output category—an aggregate 16.6% vs. 7.7%, with the gap widest on tables (42.6% vs. 10.6%). Which model "wins" flips entirely depending on what you measure.The most important finding: on prompts where requirements conflict with each other, the condition that most closely mirrors real production, the gap between the two models explodes to 26 points. That's not on a standard benchmark. That's only visible if you deliberately test it.
The Problem No One Benchmarks For
Every frontier model release comes with leaderboard scores: MMLU, HumanEval, GPQA. But when these models go into production, the failures that actually break pipelines usually aren't about knowledge. They're about compliance.
Can the model return valid JSON when asked for JSON? Include exactly the keywords specified? Stay under the word count? Do all of the above simultaneously?
If you've built anything with LLMs in production, you already know the answer is "sometimes." We set out to measure exactly where "sometimes" breaks down, and why.
How We Evaluated
278 prompts, each designed by human experts to test specific instruction-following patterns. Every response was scored by three independent annotators, majority vote as the final score, validated through a QC layer calibrated against a gold-standard dataset.
Two models evaluated under identical conditions: Gemini 3.0 Pro Preview and GPT 5.2 High. Same prompts, same decoding configuration, same rubric.
Each response was scored on two dimensions using a 5-point scale:
Prompts were structured to vary across constraint type, output format, and how multiple requirements interact. Critically, some prompts introduce deliberate tension between requirements, and some are genuinely contradictory, where full satisfaction is impossible. The right answer to a contradictory prompt isn't to try harder; it's to recognize the conflict and flag it.
The Headline Numbers
GPT 5.2 High outperforms Gemini 3.0 Pro across both dimensions, but the top-line score conceals the more interesting story.
The Distribution Tells a Different Story Than the Average
The aggregate scores say GPT wins. The score distribution says it's more complicated.
Both models cluster heavily at scores 4 and 5. Outright failures (scores 1–2) are relatively rare. But the shape of the distribution is fundamentally different:
.avif)
.avif)
GPT's distribution is spread out. It reaches score 5 more often, but its low-end tail (6.1% at scores 1–2) is nearly 6× Gemini's (1.1%). Gemini's distribution is compressed: it peaks at 4, rarely hits 5, but almost never collapses below 3.
This is the difference between peak performance with inconsistency and consistent reliability with a lower ceiling.Part of GPT's low-end tail likely reflects contradictory prompts where Gemini scores a middle-of-the-road 3 or 4 by silently compromising, while GPT either flags the conflict and scores 5 or misreads it entirely and scores low.
For production, this trade-off is the decision that matters. Not which model's average is higher, but which failure profile your pipeline can tolerate.
Where Models Actually Break
1. Counting Is Unreliable
Constraints requiring specific numbers (word counts, sentence counts, item counts) fail at disproportionately high rates:
- Sentence counts: 40% failure (GPT) vs. 28% failure (Gemini)
- Word counts: 18.8% failure (GPT) vs. 27.4% failure (Gemini), with a ±5% tolerance
- Item counts ("list exactly 3 points"): most reliable counting mechanism for both models
The counting advantage flips by type. Gemini is better at sentence counts; GPT is better at word counts. There is no single "better at counting" model.
2. Keyword Constraints: A Gradient of Difficulty
Not all keyword constraints are equally hard. To understand better, let’s check failure rate of both Gemini and GPT:
- Simple inclusion ("mention 'AI'"): GPT (12.5%) vs Gemini (10.5%)
- Keyword frequency ("include 'AI' exactly 3 times"): GPT (16.9%) vs Gemini (24.7%)
- Forbidden words ("do not use 'sorry'"): GPT (14.6%) vs Gemini (25%)
The negation gap is the sharpest finding here. For Gemini, telling it what not to say fails at 2.4× the rate of telling it what to say. For GPT, the gap is much smaller. If your system prompt relies on forbidden-word guardrails, expect them to leak, and the leak rate is model-dependent.
3. Structured Formats Are Not Natural Language
.png)
Across the full format-constrained set of 379 task instances, Gemini's aggregate format violation rate is 7.7% vs. GPT's 16.6%. GPT 5.2 High, which scored higher overall, shows consistently higher format violation rates than Gemini 3.0 Pro across every output format category. The gap is widest on tables, GPT's 42.6% violation rate is 4× Gemini's 10.6%. On structured data, GPT fails at 17.6% vs. Gemini's 7.8%. Even on prose and lists, where both models are more reliable, GPT's violation rate is nearly double Gemini's. GPT 5.2 High appears to prioritize semantic correctness over format compliance, it understands your intent better but is less careful about packaging it how you asked.
If your pipeline routes model outputs into downstream parsers, format reliability matters more than general intelligence. The smarter model is not always the safer one.
The Finding That Standard Benchmarks Hide
This is where the data gets most consequential.
We deliberately designed prompts across three conflict conditions:
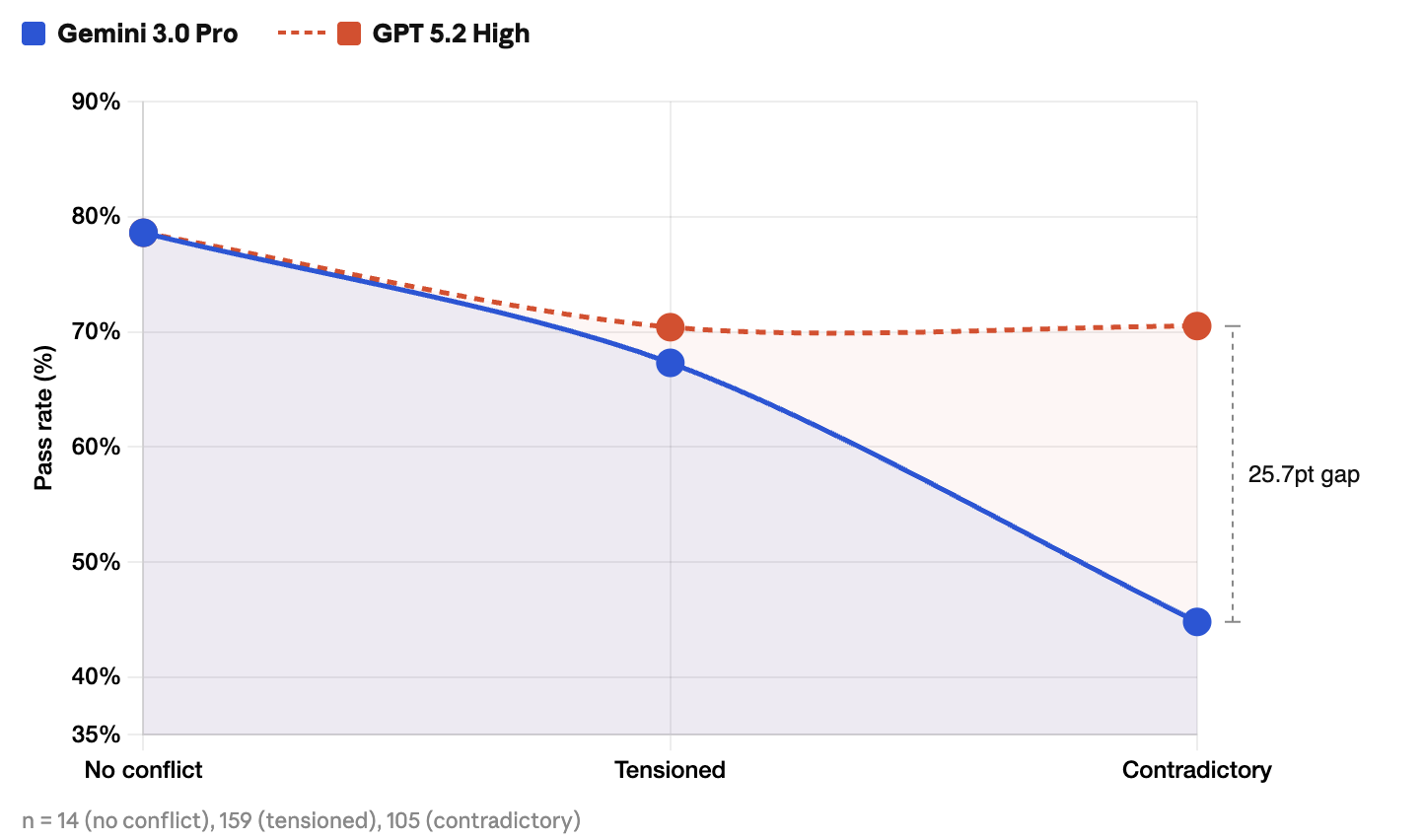
The models are nearly indistinguishable on clean instructions. The gap widens under tension. On contradictory prompts, it explodes.
GPT 5.2 High holds steady at ~70% across all three conditions. It recognizes conflicts, flags them, and proposes a path forward. Gemini 3.0 Pro collapses from 78.6% on tensioned prompts to 44.8% on contradictory ones, more often silently attempting to satisfy both requirements and producing outputs that fully meet neither.
Patterns That Cut Against the Obvious Story
A few findings that complicate the "GPT is better" narrative:
Gemini wins on format reliability, despite losing on overall score.
30 total violations vs. 63. If your use case demands valid JSON or clean table output, Gemini may actually be the safer choice, despite scoring 11 points lower overall.
GPT on impossible tasks outperforms Gemini on merely difficult ones.
GPT's pass rate on contradictory prompts (70.5%) exceeds Gemini's pass rate on tensioned prompts (67.3%). A model that can recognize and navigate an impossible instruction will score higher on that than a model trying hard at a hard one.
Keyword inclusion is the great equalizer.
Failure rate of 10.5% (Gemini) and 12.5% (GPT), simple "mention this word" constraints are the narrowest gap in the entire study. The divergence only appears when constraints get more precise or rigid.
What This Means for How You Build
Prompt design is constraint engineering. Different constraints fail in different ways.
- Test JSON and tables directly.
- Treat exact keyword frequency as brittle.
- Use item counts over sentence or word counts when precision matters.
When requirements conflict, specify which one takes priority. Model choice should follow the workflow: Gemini is often safer on format fidelity, while GPT is stronger when prompts contain conflicting requirements. Automated checks help, but they miss intent. You need to measure both compliance and comprehension.
What This Is Not
This is not a comprehensive model ranking. It evaluates a specific capability - Instruction-following under controlled, multi-constraint conditions.
- Results reflect a fixed prompt set; different prompt designs may shift relative outcomes
- Single-turn, static evaluation. Multi-turn and tool-augmented settings may behave differently
- 278 prompts is a diagnostic, not a statistical power study
Why Instruction-Following Evaluation Matters
In production, the limiting factor is often not capability but reliability. Instruction-following determines whether a model can actually meet the requirements a workflow depends on. That is why evaluation has to go beyond aggregate benchmark scores. It should test specific constraint types, separate compliance from comprehension, and reflect the messiness of real prompts. Otherwise, a model that looks strong in the abstract can still fail in the exact way your pipeline cannot tolerate.
Extended results and methodology will be published in an upcoming academic venue.
Acknowledgements
Sai Nivas, Sohini Gangopadhyay, Naushad, Huda Fatima, Jagadeesh
%20(1).png)
.png)