We’re excited to share that Deccan AI has raised $25M in a round led by A91 Partners, with participation from Susquehanna International Group and Prosus Ventures.
The hardest problem in AI right now isn't intelligence. It's accuracy.
It's a lived insight. One that comes from years of enabling frontier labs with the post-training datasets needed to push model capabilities across agentic workflows, coding, multimodal, STEM, and more.
But capability on a benchmark and reliability on real, multi-step tasks in production are not the same problem. The gap isn't a data quality issue, it's a limit of what supervised signals can teach.
Closing that gap requires models to learn from outcomes inside real environments. Our STARK RL environments are built for that. The accuracy problem doesn't stop at model training. In production, it manifests as behavioral drift, silent breakage due to model updates, and evals that miss edge cases at scale.
Years spent solving hard post-training problems at the frontier turns out to be the right preparation for it. The frontier moves at breakneck speed, so all your effort goes into matching the sheer velocity of the big labs and those learnings compound in ways that leave you better equipped for every problem downstream.
That's why we're expanding our enterprise offerings as well, with Helix, our hybrid human and AI eval and observability suite, and EnterpriseOS, our bespoke agentic platform for AI transformation.
To understand what we call superaccuracy and how it connects all our endeavours, read on.
Why Just More Data Isn’t the Answer
We started with data annotation. Expert-led SFT, high-quality evals, and domain expertise from the best practitioners in each field. It remains the foundation for everything we’re building.
Because domain-specific SFT data and evals is what gets a model to the baseline at which reinforcement learning becomes viable. The quality of the SFT checkpoint sets the ceiling for what RL can achieve.
That's why we continue to invest heavily across six domains: coding, physical intelligence, agentic, functional stream, multimodal, and model alignment. Each domain has its own taxonomy, SME-authored tasks, and quality bar.
Across all of them, every dataset is grounded in real workflows rather than synthetic proxies, verified at multiple layers before it ships, and built to expose edge cases.We deliver at scale without trading the quality discipline.
This will improve model performance, but only to a point. The ceiling isn't a data quality problem. It's a task complexity problem. Annotation captures what good looks like. It doesn't capture how a model should operate when a task is long, stateful, and requires recovery mid-sequence.
That's why we’re also investing in building behavior-driven systems built on reinforcement learning. Our domain expertise only moves upstream, from defining good outputs to designing the environments and tasks models learn from.
In behavior-driven systems, the model learns from trajectories inside real environments. The feedback signal comes from what the environment returns when the model acts.
We call this Superaccuracy. Accuracy that holds across the full sequence, not just at each individual step, but at task completion.
The Full Stack Infra for Superaccuracy
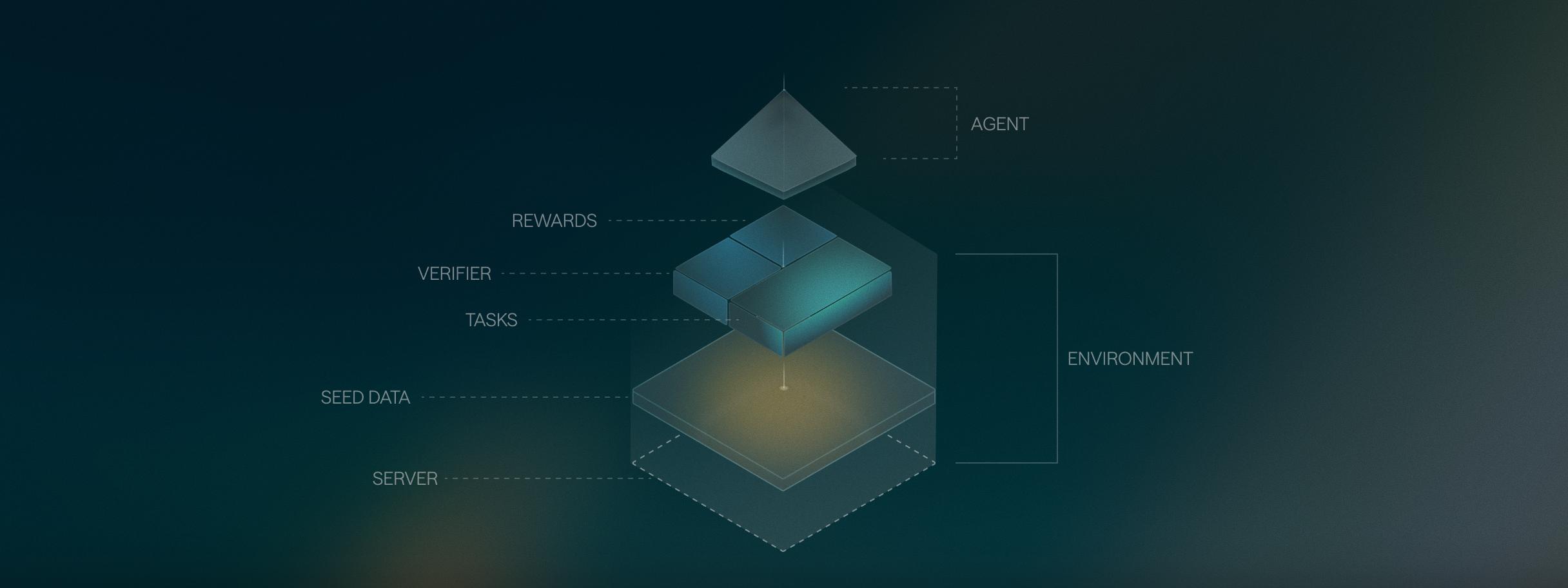
In addition to pristine data, behavior-driven systems require a loop. No environment captures everything production will throw at a model.
Over the past year, we built that loop, each layer revealing what the next one had to be.
STARK: High-fidelity RL environments to train and evaluate your models
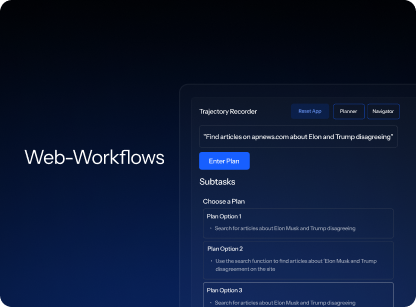
STARK RL environments provide the training ground for your models to fail without the consequences.It offers workflow-grounded training with the constraints of real systems: exact tool signatures, server statefulness, permissions, and rate limits.
Models learn from success, failure, and recovery across multi-step sequences. Multi-layer verifiers confirm whether every action in a sequence happened correctly, with every scenario written by a domain SME from workflows they run daily.
Bridging the Post-Training Gap for Physical AI
.webp)
Robotics has always been a decade-away problem for four decades. But not anymore. VLAs and world models have crossed from research curiosity to real deployment ambitions. The architectures are maturing, hardware is commoditizing, and the physical AI labs are moving fast.
The constraint though is data. Especially, the post-training layer for physical AI including human demonstrations, episode annotations, and failure labels that doesn't exist yet at any meaningful scale. That's where we're doubling down.
We're already working with some of the leading robotics companies on evaluation pipelines for real-world tasks, bringing the same rigor we've built for language model post-training into physical AI. We're expanding across the full stack: egocentric and exocentric capture, sim augmentation, factory-floor collection, and evaluation that feeds deployment signals back into training. More updates are coming soon.
Helix: Continuous Evaluation as the Control System
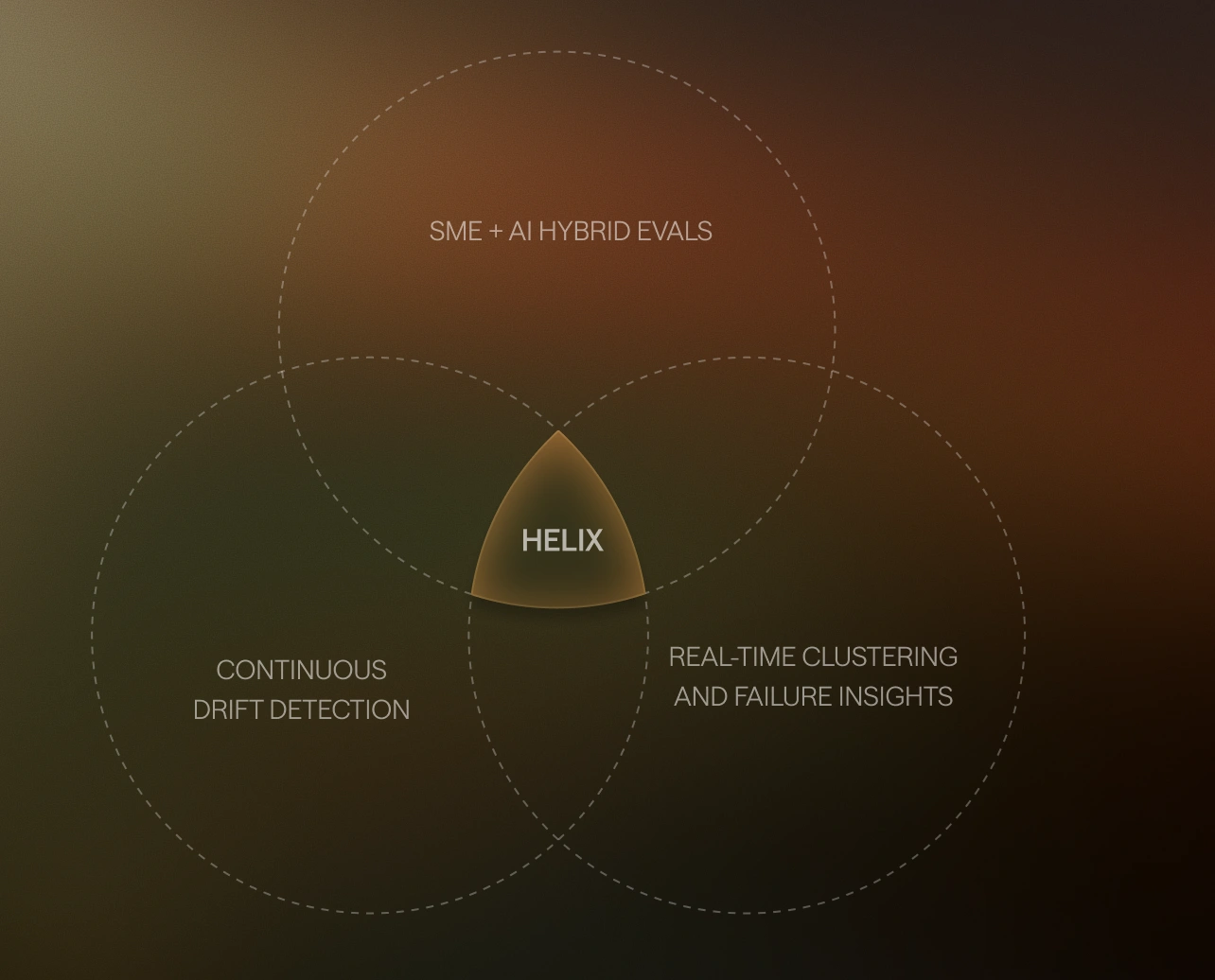
Benchmarks measure output quality on curated test sets. They don't surface what actually breaks agents in production: user behavior that keeps shifting, model updates that invalidate pre-production rubrics overnight, and edge cases that synthetic eval datasets miss.
Helix captures live production traces and scores them continuously against SME-designed rubrics. Threshold breaches trigger alerts before failures compound. Production traces are clustered by error mode in real time, showing exactly where and why agent behavior is degrading.
Every failure pattern becomes a new eval scenario, so evals stay ahead of production rather than trailing it. The best part, human involvement in your evals is configurable — run fully automated evals or route specific events like rubric breaches and model updates directly to human review.
EnterpriseOS: Enterprise AI Transformation

Finance, compliance, support, and internal operations teams, especially within GCCs, are looking to embed agents into their workflows. These functions run on volume, and the workflows that govern them — approval chains, compliance checks, exception handling — carry real consequences when they go wrong. A mistake at that scale doesn't stay isolated.
Years at the frontier has given us a unique sensitivity to how AI systems fail under real operational pressure. EnterpriseOS is built from that. Bespoke agents handle the mundane. Humans stay in the driver's seat for the judgment calls that carry consequences. EnterpriseOS runs in your own infrastructure and sharpens as it handles more of your cases.
Together, our Pristine data, STARK RL, Helix and EnterpriseOS form the full stack for reliable AI
Learn in environments → Deploy in production → Evaluate → Improve
Our 1M+ Network of Global Domain Experts
None of these function without training data honest enough to match the real world. Today, over 1M+ contributors from the Deccan experts network generate and validate the expert trajectories, edge cases, and real-world workflows that behavioral learning runs on.
What’s next for AI (And Deccan AI)
Doubling down on RL environments: We’ll expand beyond tool-use environments into browser-use and computer-use environments. We’ll also be adding support for code-based RL tasks and evaluations. Plus, we’ll continue to push the boundaries on task and verifier design for which we’ve already set the standard.
Physical AI: We're building across egocentric and exocentric data, robotics, spatial reasoning, and real-world movement evaluation — where systems must perform under real constraints.
Agent Orchestration and Observability for Enterprises: EnterpriseOS, the bespoke agentic platform for AI transformation, will continue to mature to support more targeted use-cases for back-office support operations and HR services beyond strong GCC workflows. Helix, the hybrid AI + human agent observability, will soon be available across all major marketplaces. Lots of exciting partnership announcements are coming your way.
Our commitment to Superaccuracy
We're building the layer that makes AI reliable in production, under constraints, across the tasks that determine whether AI delivers value or creates risk.
Superaccuracy matters before Superintelligence can.
We’re growing across teams. Join us to shape the foundation of superintelligence.
.png)