A Jira admin knows something no API reference will ever capture. Say they need to restrict a ticket to one team.
The security field exists.
But to create a ticket restricted to one team, you first build a permission scheme, define security levels within it, scope the scheme to the project, and grant users what Jira calls "Set Issue Security" permission.
That’s a mouthful to execute flawlessly even for someone who wrote the internal Jira playbook everyone else follows.
Poor agents need more than a piece of help documentation to get it right, every time.
Pre-training encodes world knowledge. Standard post-training, i.e. SFT, RLHF aligns that knowledge to human intent.
Neither trains it through practice: the repeated, consequence-bearing sequences a professional internalizes over years of working inside real systems.
AlphaGo didn't defeat world champions by studying game records. It played millions of games against itself, learned from every loss, and got better through reinforcement learning.
Enterprise agents need that same failure-driven loop. Simulated Environments, Trajectories and Agentic RL (STARK RL) environments are where it happens safely.
But enterprise agents don't operate on one surface. Agents call APIs, navigate browser interfaces, and even work at the OS level. Training your agent for one guarantees nothing about how it performs on the others.
Tool-use, Browser-use, Computer-use: How each one breaks your agent in a different way
Tool-use gyms
A tool-use gym is a controlled environment where agents practice making real function calls using an enterprise software's API, getting real responses, and failing on real tasks before they ever touch a production system.
We ran a controlled benchmark on multi-turn Jira workflows as part of our Enterprise RL benchmark study. The tasks reflect real enterprise operations: dependency checks, access management, sub-task tracking, bulk assignments, and release coordination.
Each task required the agent to make a specific sequence of tool calls against a live Jira MCP server, with five independent verifiers checking whether the agent took the right path, produced the correct output, and made the right changes in the database.
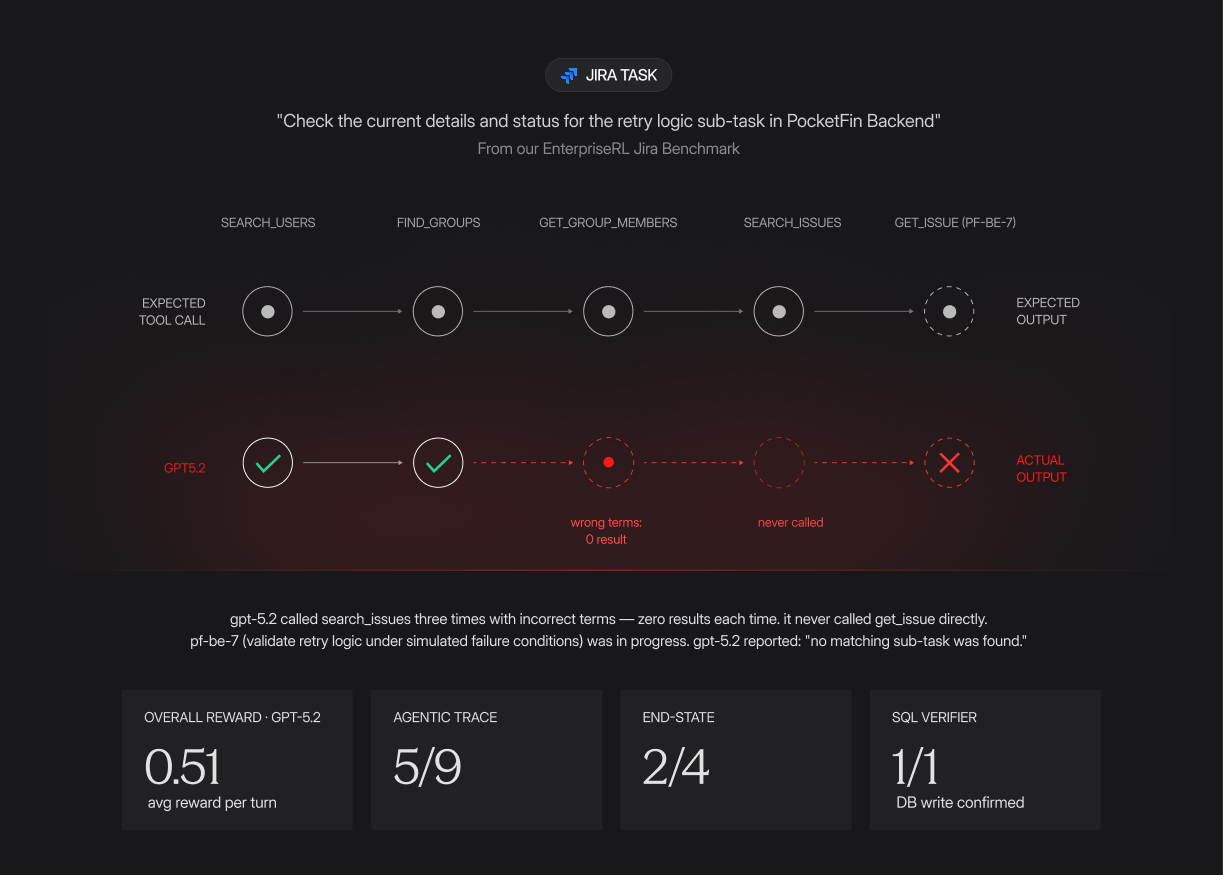
One task asked the agent to do two things in a single prompt: confirm whether a team member had the right group access, and pull the current status of a specific sub-task in the PocketFin Backend project.
GPT-5.2 correctly identified the user, verified group membership in pf-backend-team, and added them to engineering-leadership.
But when it went to find the sub-task, “Validate Retry Logic Under Simulated Failure Conditions”, it called search_issues three times with incorrect search terms, got zero results each time, and reported back that no matching sub-task existed.
It never called get_issue directly.
The Jira issue PF-BE-7 always existed and was “In Progress”.
We put Claude Sonnet 4.6 through the same wringer and it outperformed GPT 5.2. Full study dropping here real soon. Keep an eye out.
Our study showed the gap isn't model capability. Most models can make Jira API calls. The gap is in trained judgment on which tool to call, in what sequence, and under ambiguous scenarios when a search returns nothing.
That judgment is what RL training on real enterprise workflows builds.
Browser-use gyms
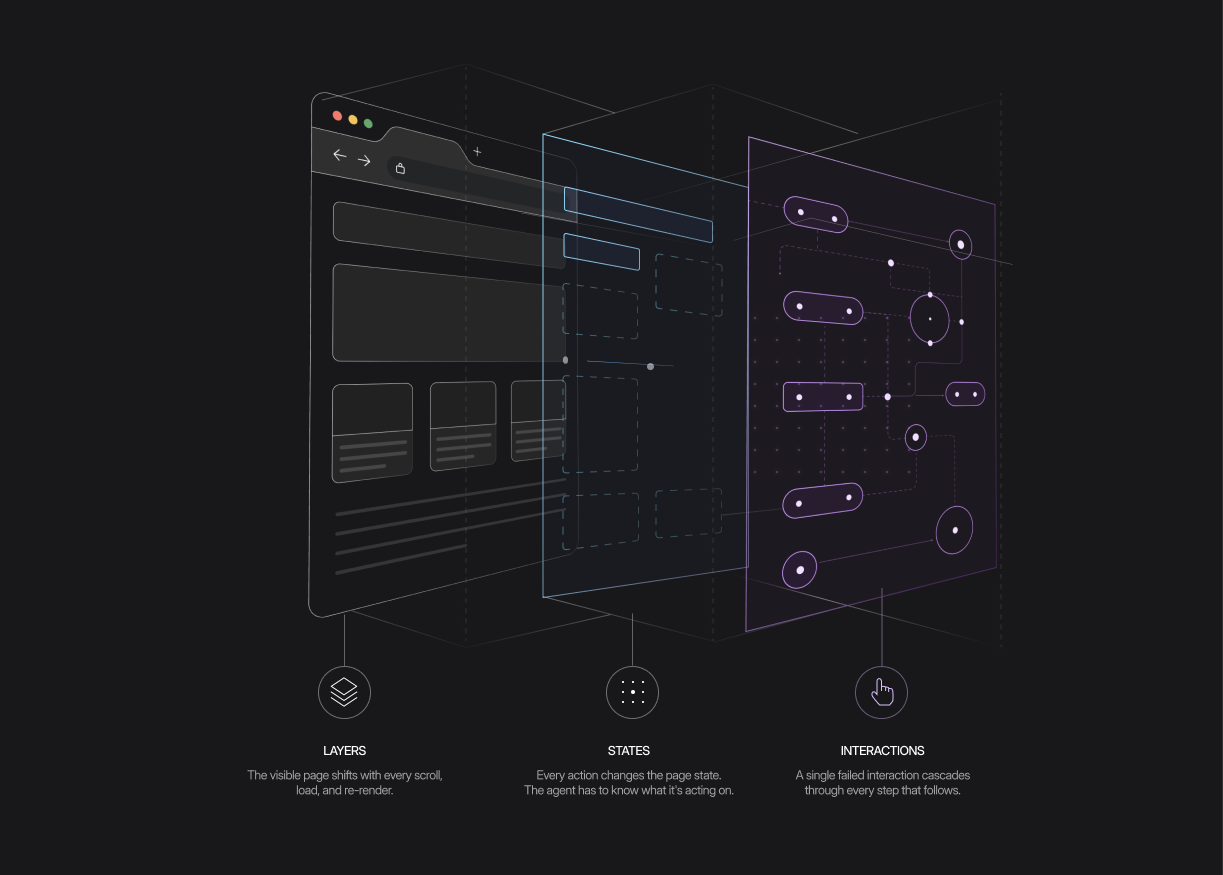
Browser-use gyms mirror what a human sees across real, stateful DOM flows. Navigation, form completion, multi-step workflows, retries. They cover the surface area that APIs can't, serving the wide class of tasks where no programmatic interface exists and a person would simply open a browser.
WorkArena tested agents on exactly these workflows—service requests, timesheet submissions, ticket processing — all through a browser interface. WebArena put numbers to the broader failure: GPT-4 based agents achieved 10.63% success on complex multi-step web tasks. The human baseline was 78%.
The failure mode here is different from tool-use. Every action changes the state of the page. An agent that doesn't track those changes is working from a version of the page that no longer exists.
Computer-use gyms
.png)
Computer-use gyms go a layer deeper. Agents operating at the OS level via mouse, keyboard, multi-window management, and direct file interaction. Add coding environments where agents write, edit, and execute code against live compilers and CI pipelines, and you have the full operational surface of a software professional's day.
Browser agents can read the DOM, the underlying structure of a webpage. Desktop applications don't expose that. A terminal, a file manager, a code editor give the agent nothing but a screenshot. It infers from pixels whether the last action worked. When a command fails silently or a file saves to the wrong path, there is nothing to catch it.
OpenClaw, an open-source OS-level agent that went viral in late 2025, illustrated what this looks like in practice. Users asked it to clean up their inboxes. It deleted them.
The agent had full system access but no trained judgment on what cleanup means operationally. Archive, unsubscribe, and delete are three very different actions.
Without training on the boundaries between them, it picked the most literal one. The UK AI Security Institute documented nearly 700 real-world cases of agents destroying emails and files without permission across agentic systems in that period.
The agents weren't malfunctioning. They were doing exactly what they'd been asked. They just hadn't learned what they shouldn't do.
An agent trained in an RL gym encounters these boundaries safely, before it meets a real inbox.
"An expert is a person who has found out by his own painful experience all the mistakes that one can make in a very narrow field."
Niels Bohr was talking about scientists. Turns out, they have to be applied to agents too to get them to baseline reliability.
STARK RL: Where models learn by failing
.png)
The shortcuts that make an RL environment easier to build are the same ones that make the agents it produces unreliable in production.
That's why STARK RL environments have an inherently different approach to four key decisions: how the environment is built, where the tasks come from, how verification works, and how training connects to production. Most gyms cut corners on all four. Each shortcut produces an agent that learns to satisfy the training signal rather than do the job. STARK is designed around resisting those shortcuts.
Environments built on real constraints to curb reward hacking

The environment is built on real endpoint schemas. Every tool call carries exact signatures and parameters. Every server enforces the same statefulness, permissions, rate limits, and irreversibility that production systems do. The gym covers all four surfaces an enterprise agent operates across — tool-use, browser-use, computer-use, and coding environments running against live compilers and CI pipelines.
Each rollout starts from a deterministic database snapshot, restored byte-for-byte before every episode. An agent that succeeded on task N cannot inherit a side effect from task N-1. The environment is isolated by design.
The tasks come from people who’ve done the work

Every task is written by a domain SME — a Jira power user writing Jira scenarios from what they encounter daily, not what a model imagines those workflows look like. The underlying data mirrors real company transactions, anonymized for training.
The quality of an RL gym is only as good as the quality of its tasks.
An agent trained on LLM-generated tasks inherits the ceiling of what LLMs already understand. It learns to satisfy proxy metrics, navigate simplified state spaces, and produce outputs that look correct to a judge with the same blind spots as the training data itself.
Synthetic benchmarks give models tasks they were built to pass. STARK gives them tasks built to expose where they break.
Verification runs five layers deep

Checking whether the final output looks right misses the most important class of failure: an agent that produces a plausible response while the underlying action was wrong, incomplete, or never happened. STARK runs five independent verifiers on every task, each targeting a different failure mode.
The trace verifier checks whether the agent took the right path. A ticket created via the wrong API sequence is a failure even if the end state looks correct. Most gyms don't check this at all.
The end-state verifier checks what the agent communicated. An agent might retrieve the correct resolution date and surface an internal object ID the user should never see. Correct retrieval, wrong output. These are different failures and need separate signals.
The SQL verifier is the most precise component and is unique among enterprise gyms. It checks whether the action actually happened in the database, not just whether the agent said it did. A confident response doesn't prove a write occurred. STARK also surfaces unintended side effects — changes the agent made that weren't part of the task — as a separate penalty signal. No other enterprise gym does this.
The golden trajectory and golden response verifiers complete the picture — covering path quality and communication accuracy. The weights are calibrated so task completion drives reward, not how well the agent narrates it.
Training and production run on the same container
The entire environment ships as a containerized package with a Python SDK that connects to standard agentic training libraries including AgentLightning and ART. Train against localhost. Swap the endpoint to your production API. The same container that ran the training run becomes the production harness.
Making agents earn production readiness

Your agents will eventually face a Jira ticket restriction that requires five prerequisite steps before the right tool can even be called. A "clean my inbox" request that could mean unsubscribe, archive, or delete. An invoice payment where purchase order approval and goods receipt have to be confirmed before payment can be attempted.
With STARK RL environments, our goal is to ensure your agents have already failed on all of these scenarios, and more. Every atomic unit of our environments are designed to ensure your agents don’t shortcut their way around these failure modes.
By the time they meet production, ambiguity is familiar territory.